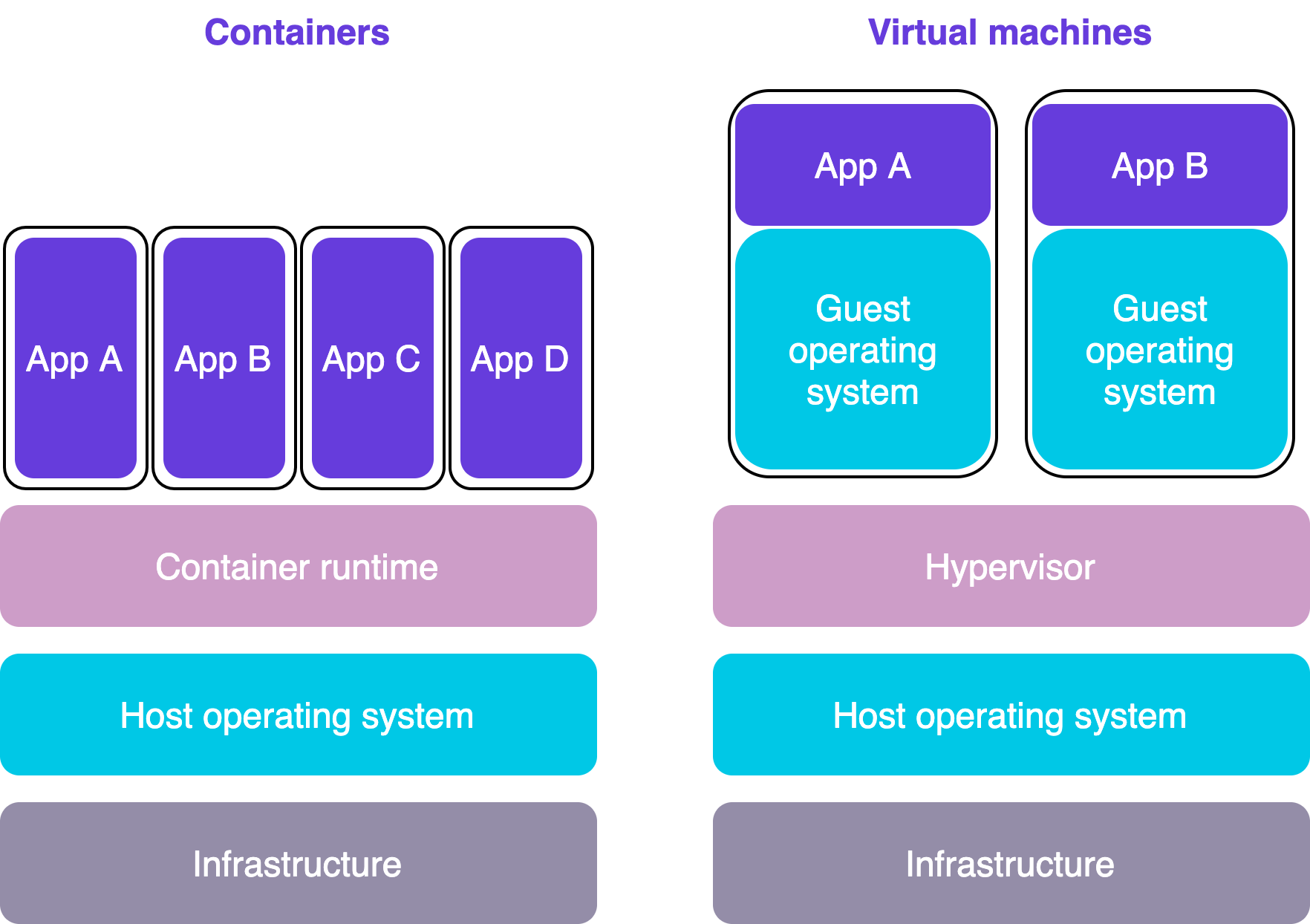
This is a series of blog posts about X-Road® and containers. The first part provides an introduction to containers and container technologies in general. The second part concentrates on the challenges in containerizing the Security Server. The Security Server Sidecar – a containerized version of the Security Server – is discussed in the third part.
Container support for X-Road – and for the Security Server especially - has been requested for some years already, but at the moment, production-level support is not available yet. However, both Central Server (xroad-central-server) and Security Server (xroad-security-server, xroad-security-server-standalone) Docker images are already available for testing purposes on NIIS’s Docker Hub account. This means that different X-Road components can be run inside containers, so why production use is not supported yet? Let’s consider the question from the Security Server’s point of view. What needs to be taken into account when running the Security Server in a container?
One process per container
According to the best practices, each container should have only one concern and run only a single process. The Security Server consists of multiple processes, including a PostgreSQL database, and the currently available Docker image runs them all in a single container. Decoupling all the Security Server processes into multiple containers would require a significant effort providing minimal benefits in exchange since the current architecture has not been designed to run and scale different application processes separately. Supporting that kind of approach would require significant changes to the Security Server architecture.
However, rules and best practices are made to be broken. After all, it is quite common to run multiple processes inside a container. A good approach for the Security Server is to deploy the Security Server application and Postgres database separately. In that way, the Security Server is split into two parts. Yet, the Security Server application processes remain in the same container. In this case, no software-level changes are required since the Security Server already supports using a remote database that can be a separate container, managed DB service on the cloud, etc.
Running multiple processes in a container requires that process management is appropriately implemented. When the Security Server is run on a Linux platform, the Security Server processes are managed using systemd service and system manager. The use of systemd is built in the Security Server packaging since it’s used by the Linux distributions supported by the Security Server. However, it is not recommended to run systemd inside a container since systemd does things that are typically controlled by the container runtime. Besides, some things systemd does are prevented inside containers by default, e.g., change host-level parameters. Therefore, the Security Server processes need to be managed using some other more lightweight process manager, such as supervisord.
Persistent storage
The Security Server is a stateful application. Therefore, the configuration in the database and on the filesystem must be persisted over a lifecycle of a single container. The data includes local overrides to the default configuration, keys and certificates, registered clients and their configuration, logs, backups, etc. Without persisting the configuration, the Security Server should be initialized, configured, registered, etc., whenever an existing container is recreated.
When an external database is used, the data in the database is already stored outside the container. However, the configuration data, backups, and message log archives stored on the filesystem must be persisted too. It can be done using persistent storage that is mounted to the Security Server container. Persistent storage stores the data on the host system and not in the container. Besides, X-Road application logs must be persisted as well. It can be done using the persisted storage or redirecting logging to console to enable the container management system to collect and store the logs.
Version upgrades
Security Server version upgrades sometimes require running database migrations and updating the contents of the configuration files. Since the way how version upgrades are handled with containers differs from traditional version upgrades done using Linux package management systems, special attention must be paid to the Security Server version upgrades. In practice, it means that the upgrade mechanism has to be built in the container image. The mechanism must detect that the application version used by the container differs from the version of the persistent configuration, and perform the steps required by the upgrade. In this way, it is possible to change from an older image to a newer one and keep the existing configuration and data.
First run
Similarly to version upgrades, there must be a mechanism that detects when a container is started for the first time, and there’s no existing, persisted configuration already available. For security reasons, each container must have a unique internal and admin UI TLS keys, certificates, and a database password. The secrets are typically generated during the installation process, which in the container context means when the image is created. In practice, it means that all the containers created from the same source image share the same secrets. In case of a public Security Server container image, anyone could access the secrets which would expose all containers created from the image to different kind of attacks. Therefore, the secrets must be recreated on the first run so that each container has its own unique set of secrets that are not shared with any other container.
Hardware security modules (HSMs)
One additional challenge that has not been discussed yet is related to hardware security modules (HSM). For extra security, sign keys and certificates of the Security Server clients may be stored on an HSM instead of a software token that’s used by default. Different cloud platforms provide cloud HSM services that can be accessed over a network, but in case using a physical HSM device is required, how to connect it to containers? Finding an answer to the question is out of the scope of this blog post.
Towards containerization
X-Road version 6 was initially designed to be deployed on Linux hosts (physical or virtual), and therefore, some additional effort is required to enable its production use in containers. However, the challenges related to containerizing the Security Server can be overcome without changing the application itself.
In the long run, the Security Server architecture should be refactored to be able to utilize the benefits that containers can offer fully. At the same time, it’s important to remember that the currently supported Linux platforms must be supported in the future too. Fortunately, the two alternatives are not mutually exclusive. Containers are not going to replace virtual machines, but they will provide an alternative way to run the Security Server.