Over the last year I’ve written multiple blog posts about X-Road and REST. In those blog posts I have shared insights on our implementations plans, details about the technical design and status updates on the progress. In the last months we’ve concentrated on the technical implementation of the X-Road Message Protocol for REST and now we’ve arrived at a point when only the finishing touches are missing from completing the first stage of the REST support implementation. Therefore, in this blog post, I’m not going to write about plans, but the actual implementation instead.
And for the readers interested in the technical details on source code level, the code implementing the REST support is now available in the develop branch of the X-Road master repository on GitHub.
For clarity, adding support for REST does not mean dropping support for SOAP. No changes are required to information systems consuming and producing SOAP services via X-Road. Instead, the two architectural styles can co-exist side by side which means that all the current SOAP services are supported in the future too.
REST support implementation
For a recap, let’s start with defining what REST means in the context of X-Road. Unlike SOAP that is a protocol with a detailed specification, REST is an architectural style consisting of the best practices and guidelines. In X-Road’s case supporting REST means consuming and producing REST-style API’s via X-Road. A loose definition would be supporting any content type over HTTP.
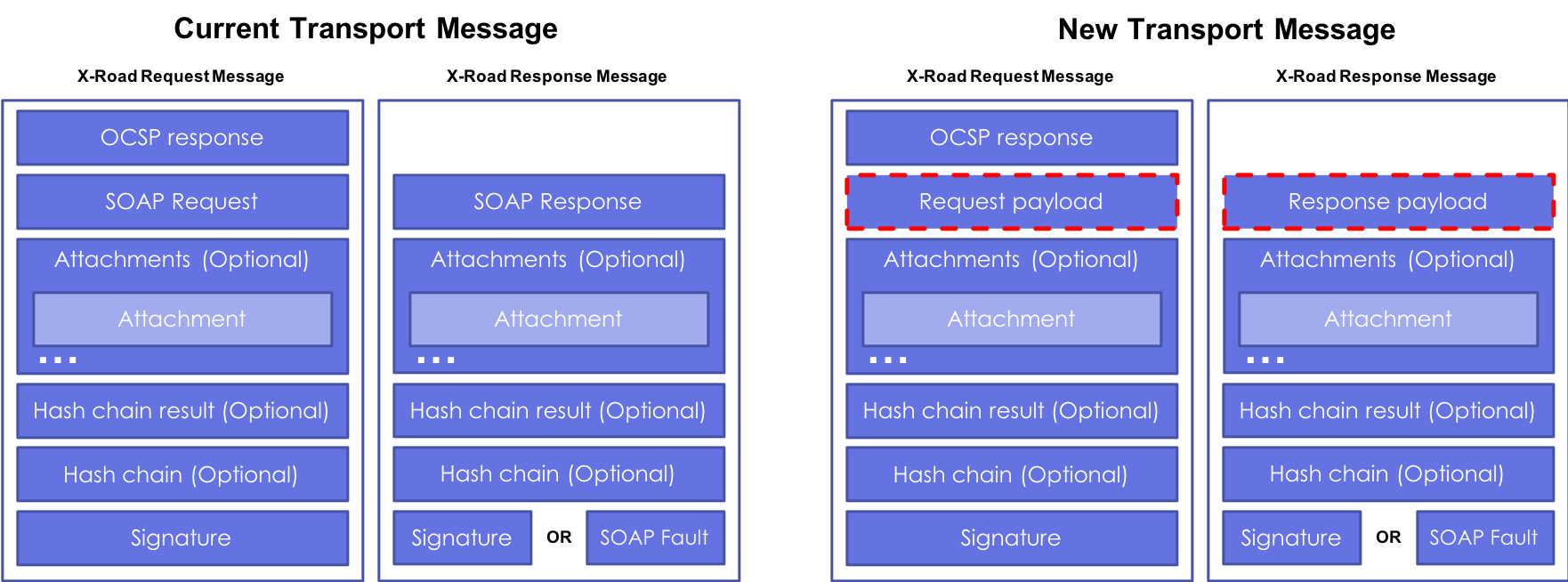
One of the guiding principles in designing the X-Road Message Protocol for REST has been the ease of use for both service providers and service consumers. Therefore, consuming and producing REST-style services via X-Road is made possible without an additional adapter service component. X-Road-specific information required by Security Server (e.g. service client identifier, service provider identifier, message id etc.) is transferred and processed so that existing REST-style services and service consumers can be connected to X-Road with minimal changes or no changes at all. This has been achieved by transferring X-Road specific information required by Security Server in HTTP headers and URL parameters, outside of the message payload.
X-Road’s REST support is not limited to just JSON and XML messages as Security Server does not set any restrictions to the content type of the payload that is transferred between a service consumer and a service provider. The content type of the payload is defined using “Content-Type” HTTP header that is transferred between a service consumer and a service provider just like the payload itself. The payload is transferred as-is, Security Server does not modify, convert or validate the processed payload. The same goes with almost all the consumer and service provider defined HTTP headers and URL parameters – they are passed as-is between a service consumer and a service provider. The list of filtered HTTP headers is included in the X-Road Message Protocol for REST specification – all the other headers are passed as-is.
When it comes to non-repudiation of REST messages, message payload, URL parameters and HTTP headers are all included in the digital signature and logs generated and verified by Security Server. Hence, X-Road guarantees non-repudiation of REST request and response messages just like it does for SOAP messages. Currently it is possible to disable logging of SOAP message body and the same feature is available for REST services too. In that case REST message payload, URL parameters and consumer/provider defined HTTP headers are excluded from the message log.
Consuming REST services
Consuming REST services via X-Road is simple – the service to be called is defined in the request URL and the X-Road client subsystem sending the request is defined in an HTTP header. Other X-Road specific information (e.g. user ID, issue, id) is optional and it is passed using HTTP headers. Other HTTP headers, path parameters and URL parameters are passed end-to-end as-is which means that from a service client’s perspective the only difference compared to a direct service call is the mandatory HTTP header defining the X-Road client subsystem.
Providing REST services
Producing REST services via X-Road is as simple (if not even simpler) as consuming services. Existing REST services can be published in X-Road as-is – it is enough to add the base URL of the REST API to be published and define access rights on the Security Server UI. Unlike with SOAP services, Security Server does not require X-Road specific information to be present in the responses returned by REST services. Certain X-Road-specific information is still included in the response message returned to a client information system, but Security Server takes care of adding the required information to response message’s HTTP headers.
Service descriptions for REST
Currently SOAP services must be described using WSDL descriptions. It is not possible to publish a SOAP service in X-Road without providing a WSDL description for the service.
In the first X-Road version including REST support (v6.21.0) service descriptions for REST services are not required. When a new REST service is added, it is enough to provide the base URL of the REST API to be published. In later versions support for describing REST services using OpenAPI 3 specification will be added.
How about automatic SOAP-REST conversions?
Services must be consumed using their native implementations – SOAP or REST. If a service provider wants to provide both SOAP and REST versions of the same service, the provider must implement both versions. In other words, Security Server will not provide automatic SOAP-REST conversion. In case automatic SOAP-REST conversion is needed, REST Adapter Service X-Road extension could be used. REST Adapter Service is an off-the-shelf component that provides an X-Road compatible REST-SOAP converter. The service supports a limited set of use cases.
Machine-to-machine authentication
The REST implementation supports mutual TLS authentication between a Security Server and a REST service consumer/provider. Support for JWT (JSON Web Token) based authentication between a Security Server and an information system may be provided in later versions.
However, it is already possible to use JWT based authentication between a service client and a service provider. As described before, Security Server passes all HTTP headers between a service consumer and a service provider as-is, so there aren’t restrictions for implementing JWT based authentication on application level.
It’s time for beta!
Soon it’s time to release the beta version of 6.21.0 that includes the long-awaited REST support. The official release version of 6.21.0 will be released at the end of April 2019. However, the beta version already provides all the REST-related features included in the final release. The last weeks are reserved for fine tuning and testing.
The version 6.21.0 will provide a basic support for consuming and producing REST services which includes:
Basic REST functionality
Message exchange with signing and time-stamping
Message logging with archiving
Downloading and verification of log records
Adding a REST service using an URL
No support for OpenAPI definitions
Operational monitoring of REST services
Service-level authorization
Certificate based authentication (clients + services)
X-Road Message Protocol for REST 1.0
That’s not all folks!
The REST support implementation will be done in phases which means that REST related features will be added along several X-Road versions – every new version adding something new. The next versions 6.22.0 and 6.23.0 will add more REST-related features later.
X-Road 6.22 (full support)
Minor fixes and enhancements based on user feedback
Metaservices for REST (listClients + listMethods)
Support for OpenAPI
Add APIs using OpenAPI specification
Meta-service for querying services' OpenAPI definitions (getOpenAPIDefinition)
Potential improvements
Path and method level authorization
JWT-based authentication (clients + services)
X-Road 6.23 or later (advanced support)
Support for URI rewriting by Security Server
Other API-Gatewayish features based on user feedback