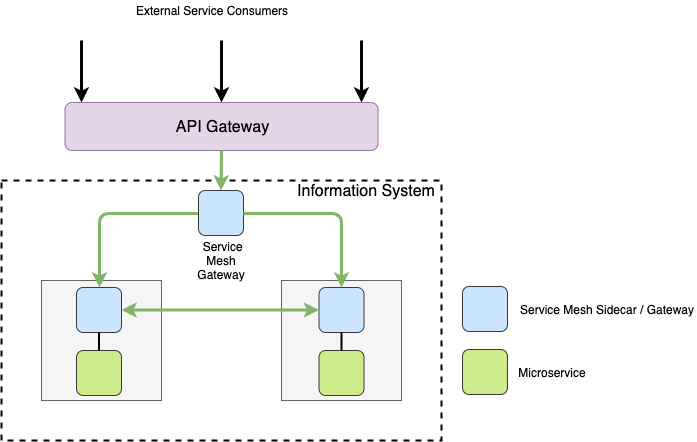
X-Road is based on a distributed architecture, which makes it extremely resilient to failure. Data is always exchanged directly between a service provider and a service consumer without third parties or intermediaries having access to it. Each data exchange party may have one or more Security Servers, but data is always exchanged between two Security Servers in a one-to-one fashion. Therefore, the failure of a single Security Server only affects services available on the Security Server in question, and all other Security Servers and services of the ecosystem remain unaffected.

Image 1. X-Road is based on a distributed architecture.
Despite the distributed architecture, an X-Road ecosystem includes components that affect the availability of all the Security Servers. The good news is that the resiliency of the ecosystem against a failure of those components can be controlled and adjusted using various measures. What are the components, and how the X-Road ecosystem can be protected against their failures? Let’s find out!
Central Server
The Central Server is one of the critical components of the X-Road ecosystem. It contains a registry of X-Road member organisations and their Security Servers. Also, the Central Server contains the security policy of the X-Road instance that includes a list of trusted certification authorities, a list of trusted time-stamping authorities, and configuration parameters. Both the member registry and the security policy are made available to the Security Servers via HTTP protocol. This distributed set of data forms the global configuration that the Security Servers use for mediating messages sent via X-Road.
To be able to mediate messages, the Security Server must have a valid copy of the global configuration available all the time. The Security Server downloads the global configuration from the Central Server regularly and uses a local copy while processing messages. The Security Server remains operational as long as it has a valid copy of the global configuration available locally. It means that the Central Server may be unavailable for a limited time without causing any downtime to the ecosystem. However, registering new members or subsystems is not possible without the Central Server.
By default, the Security Server refreshes the global configuration every 60 seconds, and the configuration is valid for 10 minutes. It means that the Central Server may be unavailable for 9 minutes without affecting the ecosystem. Once the local copies of the global configuration on Security Servers expire, the message processing stops. When the Central Server starts to publish the global configuration again, the message processing continues. However, the Security Server does not queue messages or provide support for resending failed messages. It’s a service consumer’s responsibility to resend any failed messages regardless of the reason for the failure.
The global configuration download interval is configured using the “configuration-client.update-interval” parameter on the Security Server, and the default value can be overridden locally by the Security Server administrator. Instead, the global configuration validity period is configured using the “confExpireIntervalSeconds” parameter on the Central Server by the X-Road operator, and it cannot be changed on the Security Server. Therefore, all the Security Servers that are registered to the same X-Road ecosystem respect the same global configuration validity period. The download interval and global configuration validity period should be configured according to the requirements of the X-Road ecosystem. However, it is highly recommended to increase the global configuration validity period from minutes to hours or days.
Besides, the Central Server supports high availability through clustering. A Central Server cluster consists of two or more Central Server nodes. In case one of the nodes fails, the Security Server can failover to other available nodes. In a clustered environment, only a simultaneous problem with all the Central Server nodes would cause a situation where there isn’t a valid version of the global configuration available.
OCSP responder service
A certification authority (CA) issues certificates to Security Servers (authentication certificates) and X-Road member organizations (signing certificates). Authentication certificates are used for securing the connection between two Security Servers. Signing certificates are used for digitally signing the messages sent by X-Road members. Only certificates issued by trusted certification authorities that are defined on the Central Server by the X-Road operator can be used. The information about trusted certification authorities is distributed to the Security Servers in the global configuration.
The Security Server checks the validity of the signing and authentication certificates via the Online Certificate Status Protocol (OCSP, RFC 6960). An OCSP responder service providing the status information is maintained by the certificate authority that issued the certificates. Each Security Server is responsible for querying the validity information of its certificates and then sharing the information with other Security Servers as a part of the message exchange process. Only Security Servers with valid authentication certificates and members with valid signing certificates can exchange messages. If the validity information is not available or a certificate is not valid, the message exchange fails.
To be able to mediate messages, the Security Server must have valid copies of authentication and sign certificates’ OCSP responses all the time. The Security Server downloads the OCSP responses from the OCSP responder service regularly and uses the local copies while processing messages. The Security Server remains operational as long as it has valid copies of the OCSP responses available locally, and the certificates are valid. This means that the OCSP responder service may be unavailable for a limited time without causing any downtime to the ecosystem. The period that the OCSP responder may be unavailable without affecting the ecosystem depends on various factors.
The Security Server fetches new OCSP responses using a fixed interval that is 20 minutes by default. The fetch interval is configured on the Central Server using the “ocspFetchInterval” configuration parameter by the X-Road operator. An OCSP response is considered expired by the Security Server if it was issued too far in the past OR there’s already new status information available. The validity period is defined on the Central Server using the “ocspFreshnessSeconds” configuration parameter by the X-Road operator. By default, the Security Server considers an OCSP response expired if there’s new status information available – meaning that the “nextUpdate” attribute in the OCSP response is in the past. However, the “nextUpdate” attribute can be omitted so that “ocspFreshnessSeconds” alone defines the validity period of an OCSP response. Omitting the “nextUpdate” attribute is done on the Central Server using the “verifyNextUpdate” configuration parameter by the X-Road operator.
All in all, an X-Road ecosystem’s resiliency to failures of an OCSP responder service is controlled through three configuration parameters that are all set on the Central Server by the X-Road operator and distributed to the Security Servers in the global configuration. The “ocspFetchInterval” parameter defines how often the OCSP responses are refreshed, and the “ocspFreshnessSeconds” parameter specifies the validity period of the responses, and the “verifyNextUpdate” parameter defines whether the “nextUpdate” attribute in the OCSP response is omitted. The most resilient configuration can be achieved by keeping the fetch interval short, the validity period long, and ignoring the “nextUpdate” attribute. Besides, when the “nextUpdate” attribute is omitted, it’s also possible to increase the validity period during a service break of the OCSP responder service, which buys more time to solve the problem without affecting the ecosystem.
Besides, after the first failed OCSP request, the Security Server switches from the regular OCSP fetching interval to a failure mode during which fetching OCSP responses is attempted once a minute, by default. After the first successful OCSP request, the Security Server switches back to the regular interval.
It’s also good to be aware that not all OCSP responder services include the “nextUpdate” attribute in their OCSP responses. Usually, OCSP responder services that are based on a certification revocation list (CRL) include the attribute, but real-time OCSP services don’t. A CRL based OCSP service reads certificate statuses from a static CRL that’s refreshed regularly. In contrast, a real-time OCSP service checks certificate statuses in real-time. In case the “nextUpdate” attribute is missing from the OCSP response, the “ocspFreshnessSeconds” parameter alone defines the validity period for the response just like when the “nextUpdate” attribute is omitted using the “verifyNextUpdate” parameter.
When considering the values for the three parameters, it’s essential to consider how the values affect the evidential value of the logged messages. Since the OCSP response of the signing certificate is used to check the validity of the certificate that’s used to sign messages, the age of the OCSP response may affect the validity of the signature. Therefore, it is vital to understand the consequences that enabling the use of old OCSP responses may legally have. From a technical perspective, it is equally important that the values of the three configuration parameters are aligned with each other and the policies of the certificate authority. For example, the “ocspFetchInterval” parameter must be smaller than the “ocspFreshnessSeconds” parameter, or otherwise, the Security Server considers the responses expired before new ones are fetched.
Time-stamping service
All the messages sent via X-Road are time-stamped and logged by the Security Server. The purpose of the time-stamping is to certify the existence of data items at a certain point in time. A time-stamping authority (TSA) provides a time-stamping service that the Security Server uses to time-stamp all the incoming/outgoing requests/responses. Only trusted TSAs that are defined on the Central Server by the X-Road operator can be used. The information about trusted TSAs is distributed to the Security Servers in the global configuration. The approved time-stamping authorities must implement the time-stamping protocol (RFC 3161) supported by X-Road.
By default, X-Road uses batch time-stamping, which means that new messages that have been processed since the previous batch time-stamping and do not have a time-stamp yet, are time-stamped once a minute. The time-stamping interval is defined on the Central Server using the “timeStampingIntervalSeconds” parameter by the X-Road operator, and it cannot be changed on the Security Server. If the time-stamping fails, the Security Server continues to process messages until the acceptable time-stamping failure limit is reached. By default, the limit is 4 hours, and it’s configured on the Security Server using the “message-log.acceptable-timestamp-failure-period” parameter. The default value can be overridden locally by the Security Server administrator. When the limit is reached, the Security Server quits processing messages. When the time-stamping service becomes available again, all the messages missing a time-stamp are time-stamped, and the Security Server continues normal operations.
Besides, after the first failed time-stamping attempt, the Security Server switches from the regular time-stamping interval to a failure mode during which time-stamping is attempted once a minute, by default. After the first successful time-stamp, the Security Server switches back to the regular time-stamping interval.
The Security Server also supports automatic failover between time-stamping services if it has more than one configured time-stamping service. It means that the Security Server tries time-stamping with all the configured services until time-stamping succeeds or all the configured services have failed. The behavior is repeated for every batch.
Alternatively, the Security Server can be configured to time-stamp messages synchronously. It means that every message is time-stamped immediately, and if time-stamping the message fails, processing the message fails too. In case a security policy requires that every processed message is time-stamped within a defined time window, this configuration option can be used to guarantee it. However, the downside of synchronous time-stamping is that it increases the load of the time-stamping service tremendously compared to batch time-stamping. When the batch time-stamping is used, the load does not depend on the number of messages exchanged over the X-Road. Instead, it depends on the number of Security Servers in the system. Another downside of the synchronous time-stamping is that it increases the processing time of each message since the time-stamping is done synchronously as a part of the message processing flow. It means that four time-stamping operations are added to the end to end processing time of each message.
All in all, an X-Road ecosystem’s resiliency to failures of a time-stamping service is managed through different factors. The time-stamping interval and number of available time-stamping services are defined on the Central Server by the X-Road operator. Instead, the acceptable time-stamping failure period and the time-stamping mode (batch / synchronous) are defined on the Security Server, and the default values can be overridden locally by the Security Server administrator. The most resilient configuration can be achieved by using batch time-stamping, keeping the time-stamping interval short, keeping the acceptable time-stamping failure period long, and configuring multiple time-stamping services on the Security Server.
However, just like with the OCSP related configuration, it’s essential to consider how the selected values affect the evidential value of the logged messages. For example, the age of a time-stamp may affect its evidential value from a legal perspective. Also, whether it is acceptable to have messages without a valid time-stamp must be considered, and the time-stamping mode (batch / synchronous) should be selected accordingly.
Conclusions
An X-Road ecosystem is exceptionally resilient to failure. Different components may fail separately or at the same time, and the ecosystem is still capable of processing messages and transferring data. How long a single component may be unavailable without affecting the ecosystem depends on the configuration of the ecosystem and the configuration of individual Security Servers. The X-Road operator is responsible for defining and managing the ecosystem’s configuration. Still, the Security Server administrators may define some configuration items locally since the requirements may vary between organisations and Security Servers.
The values of different configuration items vary between X-Road ecosystems, and they depend on the requirements and constraints regarding availability, the evidential value of the logs, costs, etc. Also, financial factors play a role when defining the OCSP fetch interval and time-stamping interval since some commercial trust service providers request a transaction-based fee for the use of their services. In those cases, costs can be optimized by adjusting the intervals without forgetting the legal requirements regarding the age of the OCSP responses and time-stamps. All in all, the configuration should be in balance between different requirements and constraints. Sometimes it may require compromises between objectives.