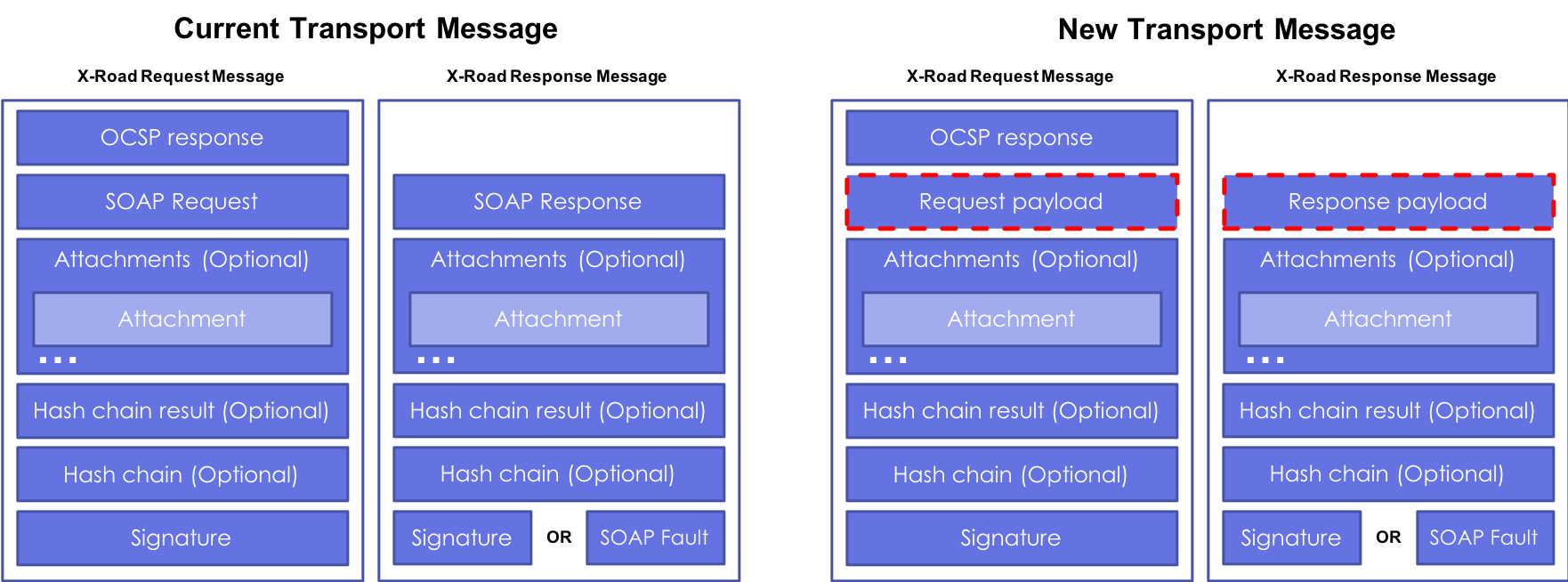
X-Road is a centrally managed distributed data exchange layer between Information Systems that provides a standardized and secure way to produce and consume services. The identity of each organization and Security Server is verified using certificates that are issued by a trusted Certification Authority (CA) when an organization joins an X-Road ecosystem. The identity of service producers and consumers is maintained centrally, but all the data is exchanged directly between a consumer and a provider.
X-Road’s distributed architecture makes it highly scalable and very resilient against different kinds of cyber attacks. X-Road creates a trusted network where message exchange takes always place between two trusted parties as the identities of all message exchange parties are verified using certificates. In general, these are major strengths of X-Road, but in some cases they’re also weaknesses, because they make the onboarding process of new members slower compared to a standalone solution that does not require any registration or verification to be completed. In production like environments certain controls are required as they enforce trust between member organizations. However, there are situations in which more agile approach is needed, e.g. testing and development purposes.
Currently the only way to be able to test Security Server is to join an existing X-Road ecosystem or set up an own environment. The time that is required for completing any of the two alternatives depends on the policies of an existing X-Road ecosystem and the experience level of the expert who is responsible for the task. Nevertheless, the time required for completing the task varies from hours to days. A developer who just wants to test a new service together with Security Server would like to have a solution that is available in minutes and requires minimal configuration. Sounds too good to be true - is something like that possible?
Is this a dream or is it now?
Standalone Security Server is a special version of Security Server that is ready-to-use in minutes without the normal Security Server installation, configuration and registration process. It is meant for testing purposes in X-Road service development and it cannot communicate with other Security Servers. Therefore, it is targeted especially to developers and organizations that are developing services to be published via X-Road.
It is possible to add new services on the standalone Security Server and invoke the services using the same Security Server. It comes with two pre-configured subsystems – one for providing and another for consuming services. In addition, it does not require connection to Central Server, OCSP service or time-stamping service. Therefore, standalone Security Server can be set up in minutes and once it has been downloaded it does not even require an internet connection. It is ideal for testing purposes in service development or for someone who’s interested in giving a quick try.

Image 1. Standalone Security Server.
Standalone Security Server has not been published yet, but a proof of concept (PoC) level implementation has been completed by NIIS. Before publishing the standalone Security Server we would like to hear X-Road community’s opinion regarding the format in which it should be published. Do you want to have it as a Docker image, VirtualBox image, AWS AMI, Azure virtual machine image or something else? NIIS is going to publish a standalone version of Security Server using the format that receives the most votes.
NIIS welcomes everyone to give their vote by 1st November 2018!