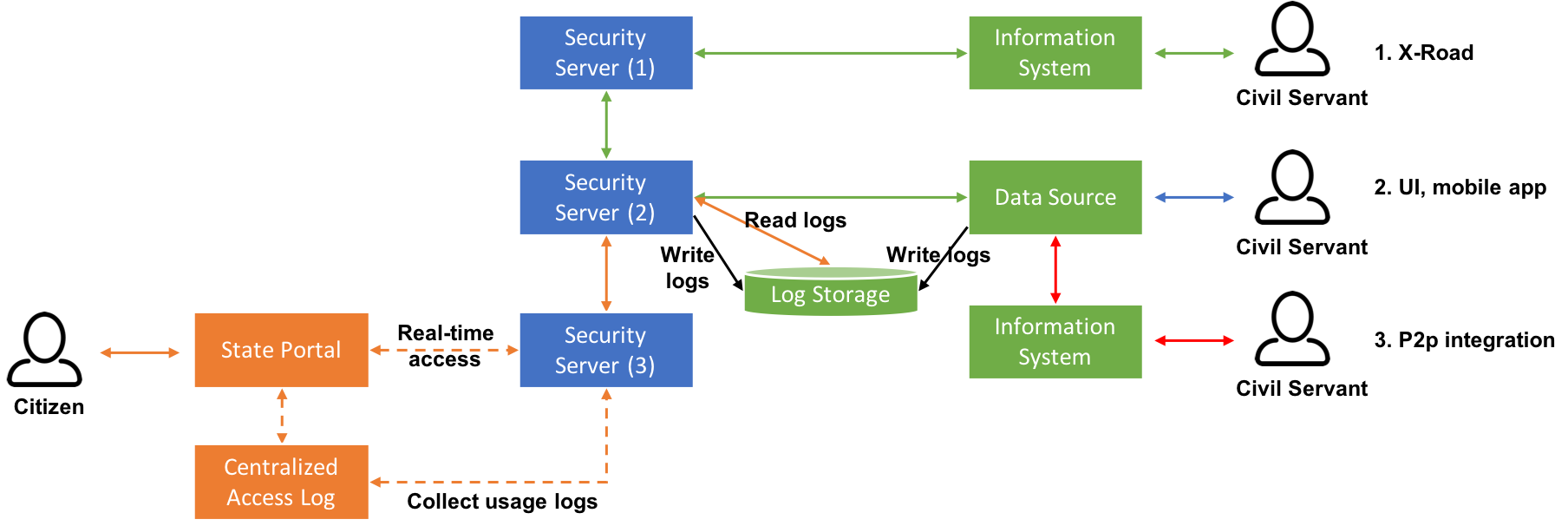
In general, load balancing means distributing workloads across multiple computing resources. Instead of relying a single resource the same service is deployed on multiple resources and service requests are distributed across all of them. If one of the resources stops responding, no more requests are routed to it and other available resources take care of serving the requests. Load balancing is used to increase performance and availability using multiple components instead of a single one. Load balancing can be implemented in different ways – a load balancer can be software or hardware based, DNS based or a combination of the previous alternatives. In addition, load balancing can be implemented on client or server side.
X-Road Security Server has an internal client-side load balancer and it also supports external load balancing. The client-side load balancer is a built-in feature and it provides high availability. Support for external load balancing has been available since version 6.16.0 and it provides both high availability and scalability from performance point of view.
Internal load balancing in X-Road
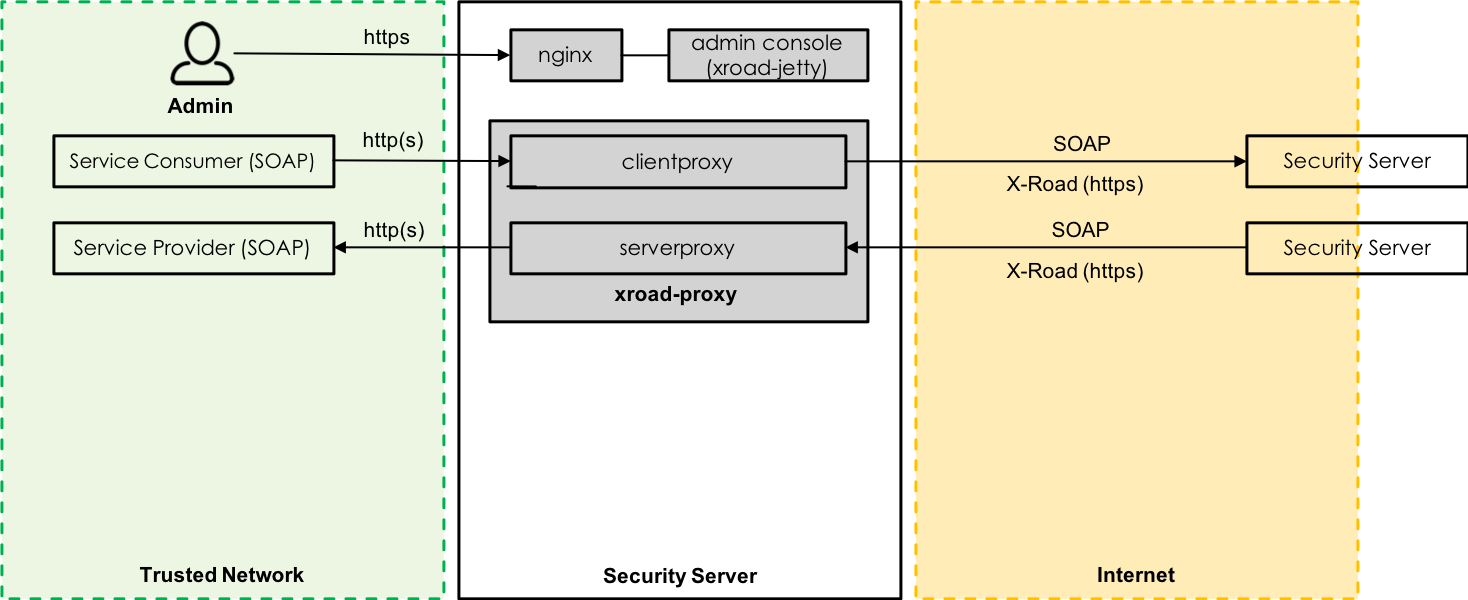
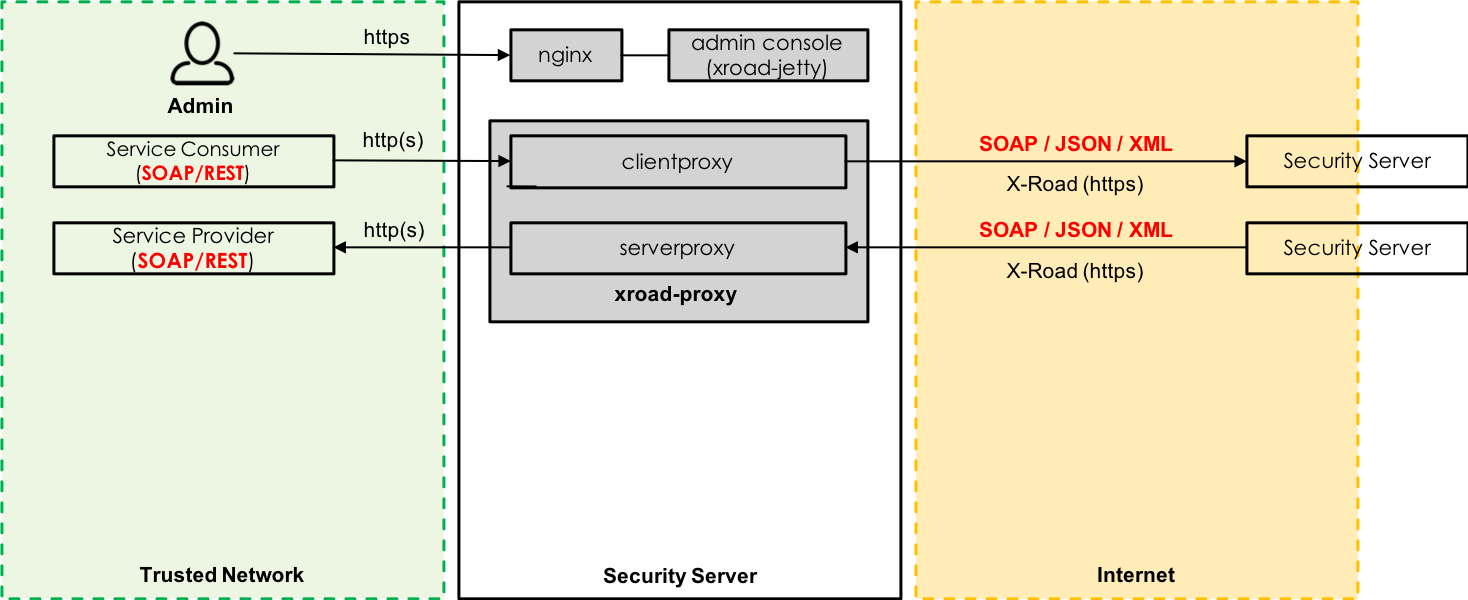
The internal client-side load balancer is a built-in feature of the X-Road Security Server and it is operating on “Fastest Wins” basis. When a service is registered on multiple Security Servers (same organization, same subsystem, same service code) the server that responds the fastest to TCP connection establishment request is used by a client Security Server. Once a provider Security Server is selected, it will be used for subsequent requests by the client until the TLS session cache expires or a connection attempt fails.

Image 1. “The Fastest Wins” - the server that responds the fastest to TCP connection establishment request is used by a client Security Server.
If the fastest Security Server providing the service quits answering, the client Security Server will automatically change to the second fastest and so on. Connections are evaluated on TCP level only so higher-level application related problems are not taken into account.

Image 2. If the fastest service provider fails, the client will automatically change to the second fastest.
The solution provides high availability, but not scalability from performance point of view as the load is not evenly distributed between all the provider side Security Servers. However, this does not mean that all the different client Security Servers would use the same provider Security Server. The client Security Server prefers the provider Security Server that is nearest network-wise (round trip time is lowest) and the fastest provider varies between different clients. In other words, load generated by different client Security Servers is distributed between different provider Security Servers, but the distribution is not based on a load balancing algorithm so there’s no guarantee that the load is distributed evenly.

Image 3. Load generated by different client Security Servers is distributed between different provider Security Servers.
When relying on internal load balancing adding a new node means installing and registering a new Security Server. Each Security Server serving the same service has its own identity which means that it has its own authentication and sign certificates. In addition, each Security Server providing the same service is stand-alone and there’s no automatic synchronization regarding registered services and/or service level access permissions between Security Servers. Maintaining and synchronizing configuration between Security Servers is a manual task.
Internal load balancing is completely transparent to the client-side information system as the client Security Server takes care of routing the requests, verification of certificates etc. internally. For the client-side information system it’s enough to send a request to the client-side Security Server and it will take care of the rest using the global configuration data provided by the Central Server for discovering Security Servers that provide the requested service. This makes it possible to add new provider Security Servers and/or change the network location of existing provider Security Servers without making any changes on the client-side. High-security environments, where all the outgoing network connections are blocked by default and only connections to whitelisted targets are allowed, are an exception as all the new provider side Security Servers must be explicitly whitelisted on firewall configuration.
External load balancing in X-Road
First, let’s define the meaning of external load balancing. In this context, external load balancing means that a third-party software or hardware-based load balancer (LB) is used for distributing load (LB 1-2) between an information system and the X-Road Security Server or (LB 3) between Security Servers. There are three different use-cases that include an external load balancer:
A load balancer (LB 1) between service consumer(s) and a Security Server cluster.
A load balancer (LB 2) between service providers and a Security Server cluster or a single Security Server.
An external internet-facing load balancer (LB 3) that distributes inbound requests from other Security Servers to a Security Server cluster.

Image 4. An external load balancer can be used in three different scenarios. Different scenarios can also be combined.
The first two scenarios are about distributing load between the Security Server and an information system and they have always been supported by the Security Server. Therefore, we’re not going to concentrate on them now. Instead, let’s take a better look at the third use-case.
The Security Server has supported the use of an external internet-facing LB since version 6.16.0. In this setup an external LB is used in front of a Security Server cluster and the LB is responsible for routing incoming messages to different nodes of the cluster based on the configured load balancing algorithm. Using the health check API of the Security Server the LB detects if one of the nodes becomes unresponsive and quits routing messages to it. The solution provides high availability and scalability from performance point of view.

Image 5. An external LB can be used in front of a Security Server cluster and the LB is responsible for routing incoming messages to different nodes.
A Security Server cluster can have undefined number of nodes which are all active (not hot standby). From client Security Server’s point of view a cluster looks like a single Security Server as all the nodes have the same identity (server code, certificates etc.) and they’re all accessed using the same public IP that is registered to the global configuration as the Security Server’s address. Therefore, a cluster is completely transparent to client-side information systems and Security Servers.
When a clustered Security Server acts as a client and makes a request to an external server (Security Server, OCSP, TSA, Central Server), the external server sees the public IP address. However, the public IP address used for outgoing requests might be different from the one used for incoming requests.

Image 6. When a clustered Security Server acts as a client and makes a request to an external server, the external server sees the public IP address.
One of the nodes is the master node and all the other nodes are slaves. Maintaining a cluster’s configuration is easy, because configuration changes are done on the master and they’re automatically replicated to the slaves. Replication covers the configuration database and configuration files. Changing the configuration on the slaves is blocked. However, all nodes fetch global configuration and OCSP responses independently. In addition, message log database is Security Server specific and it is not replicated between nodes.

Image 7. Serverconf database and configuration files are automatically replicated from the master to the slaves.
Support for an external LB has not been designed some specific LB solution in mind. Any software or hardware based LB that supports HTTP health check and load balancing TCP traffic can be used, e.g. AWS ELB, F5, HAProxy, Nginx. The LB uses the health check API of the Security Server for checking the state of all the nodes in a cluster. The health check API has been available since version 6.16.0 and it can be used for monitoring purposes as well. Health check returns HTTP 200 OK when security server is operating normally, otherwise HTTP 500. The health check API must be enabled manually as it is disabled by default.
The use of an external internet-facing LB also enables dynamic scaling of a Security Server cluster. Dynamic scaling means that the number of nodes in the cluster can be automatically adjusted based on the selected metrics, e.g. CPU load, throughput of incoming requests etc. Scaling can also be done based on a predefined schedule – the number of nodes varies between time of the day and day of the week, e.g. number of nodes is increased during peak hours and decreased for the night. As all the nodes in the cluster share the same identity, adding a new node can be automated because it doesn’t have to go through the normal registration process that requires manual work. Changing the number of nodes can be done creating/deleting nodes or starting up/shutting down existing nodes. Either way, less resources are consumed compared to a situation where enough resources for handling the peak load are running 24/7.
Clustering enables dynamic scaling of Security Servers, but the X-Road does not provide off-the-shelf tools for the implementation as the implementation is platform specific. For example, Amazon Cloud Services (AWS) Auto Scaling and Elastic Load Balancer (ELB) services can be used to implement dynamic scaling and other cloud platform providers (Microsoft Azure, Google Cloud Platform etc.) have similar services.
Which one to use?
Compared to the X-Road's Security Server’s internal load balancing feature, an external load balancer provides better support for high availability and scalability from performance point of view. External load balancer gives the provider side Security Server owner full control of how load is distributed within the cluster whereas relying on the internal load balancing leaves the control on the client-side Security Servers. However, setting up a Security Server cluster is more complicated compared to internal load balancing that is a built-in feature and enabled by default. In addition, an external load balancer brings additional complexity to Security Server version upgrades too as the upgrade process must be coordinated within the cluster. On the other hand, adding new nodes to a cluster is easy as the normal registration process is not required, because all the nodes in the cluster share the same identity. When relying on the internal load balancing each node is independent and has its own identity – adding a new Security Server means that full registration process must be completed.
In addition, external load balancing has one great benefit compared to internal load balancing. The Security Server health check API used by an external LB recognizes situations where a Security Server is running, but PIN code is missing. When PIN code is missing, the Security Server is not able to process messages. Internal load balancing is not able to recognize this situation as it is operating on the TCP level – establishing a TCP connection between Security Servers works even if the PIN code is missing and the provider server is not able to process messages. Therefore, internal load balancing might route messages to Security Servers that are not able to process them because of a missing PIN code. This kind of situation might happen after a Security Server has been restarted, but the administrator hasn’t entered the PIN code yet. Fortunately, there’s an easy solution to the missing PIN code problem. Entering PIN code can be automated using xroad-autologin add-on that can be used together with both built-in and external load balancing.
After discussing different alternatives and combinations the next question probably is when different solutions should be used. The bad news is that there is no single right way to do it. The best solution is always case specific and it varies between different use-cases and information systems. Requirements regarding the availability, scalability and performance of the information system must always be taken into consideration and the solution should be designed based on them. Different alternatives can be and should be used together to provide the best overall solution.